Orchestration and tooling beat size
Kimi K2.6: Orchestration Beats Raw Scale
Moonshot’s Kimi K2.6 shows orchestration — MoE efficiency plus agent‑swarm tooling (OpenClaw/ClawBench, Agent Swarm RL) — yields outsized, task‑specific returns incumbents are overlooking.
The Daily Letter Desk
Written with LLMs · Edited by humans
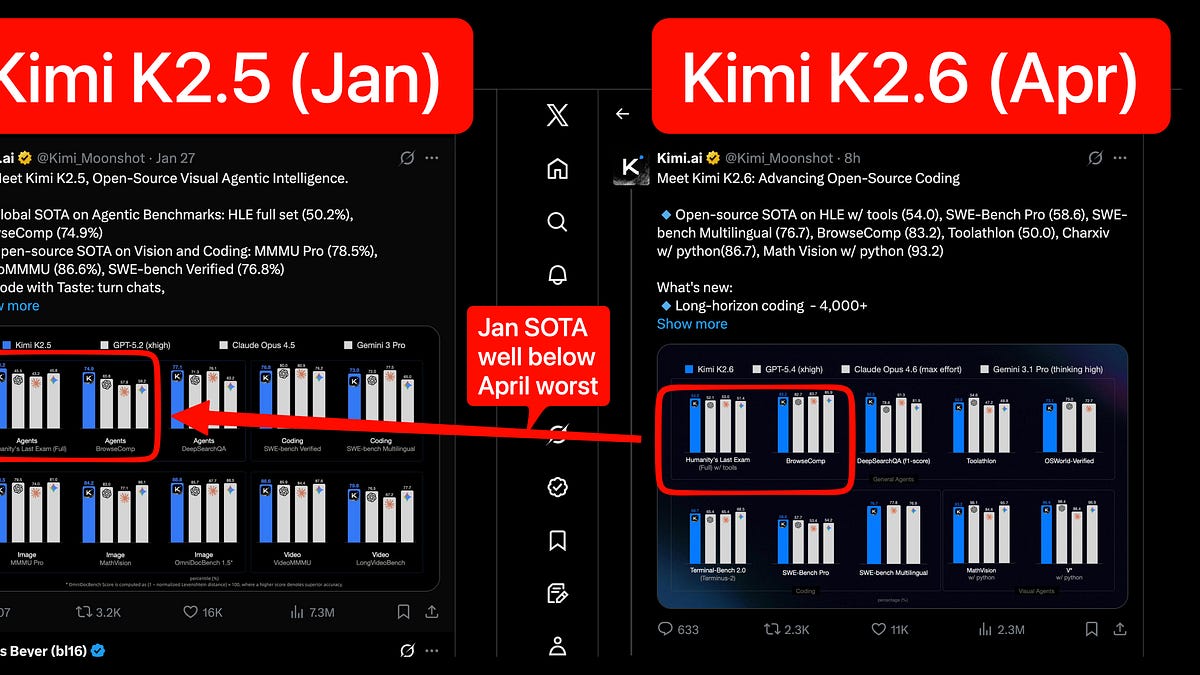
oonshot combined MoE model design with orchestration tooling and outperformed peers on practical agentic workloads. Real‑world agentic tasks reward coordination, not just larger dense models.
What happened
Moonshot released Kimi K2.6 as an open‑model refresh. The release reports a 68.6% win+tie rate versus Google’s Gemini 3.1 Pro on frontend benchmarks and emphasizes MoE‑style architecture plus agentic tooling. The project expanded its agent swarm work from K2.5, rebranded components as “Claw Groups,” and published ClawBench alongside OpenClaw integrations. Public posts and reports highlight K2.6’s strengths in long‑horizon coding runs and coordinating hundreds of agents in parallel. Moonshot paired model changes with orchestration primitives and benchmarks focused on multi‑agent, tool‑using workflows instead of chasing single‑model leaderboard records.
“Moonshot Kimi K2.6: the world's leading Open Model refreshes to catch up to Opus 4.6 (ahead of DeepSeek v4?)”
— latent.space
Why it matters
Kimi K2.6’s results show orchestration can multiply model value more reliably than parameter count for many tasks. Mixture‑of‑experts architectures improve compute and attention efficiency, but the larger leverage comes from tooling that converts many small decisions into coherent behavior. OpenClaw, ClawBench and Agent Swarm RL act as the control plane that lets hundreds of agents, toolchains, and retrievers collaborate on long‑horizon problems like autonomous coding. Incumbents have concentrated on bigger dense weights and multimodal stacks; Moonshot invested in coordination layers and benchmarks that reward them. That approach sidesteps the diminishing returns of raw scale and captures application‑level wins where customers measure value. If you’re building agentic systems, prioritize orchestration as much as backbone size.
Context
AINews notes K2.6 refreshes the lead K2.5 established in January and arrives amid renewed rumors of DeepSeek v4. The release is presented as an execution update tied to agentic tooling and benchmarks.
“Moonshot/Kimi continues to compete at a level far above “just being open source versions of Frontier models””
— latent.space
Counterpoint
AINews cautions K2.6 is “not as technically impressive in isolation as K2.5,” and Moonshot did not disclose the full extent of additional pre/post‑training. Benchmark wins can reflect engineered evaluation paths and toolset matchups that favor a specific workflow; raw leaderboard claims still matter to many buyers.
What to watch
Will ClawBench and agent‑swarm benchmarks generalize beyond engineered tool stacks? Can incumbents replicate Kimi’s orchestration gains at scale, or will their focus on monolithic models blunt adoption? Watch DeepSeek v4, reproducibility on independent toolathlon tests, and real‑world long‑horizon coding deployments.
● End of story
Want tomorrow's letter in your inbox?
One edition per day. Seven stories. Zero LinkedIn energy.